Biography
I am a post-doctoral researcher at the AI Lab of Vrije Universiteit Brussel (VUB). My research focuses on reinforcement learning (RL) and representation learning in RL. Specifically, I work on methods for delivering reliable and adaptive learning agents, especially by combining RL with world models. I am also interested in foundation models for task acquisition and generalization, as well as formal verification, abstraction, and synthesis as tools for building AI mechanisms that can justify and certify the behavior they adopt. I am also teaching the course Theory of Computation at the VUB.
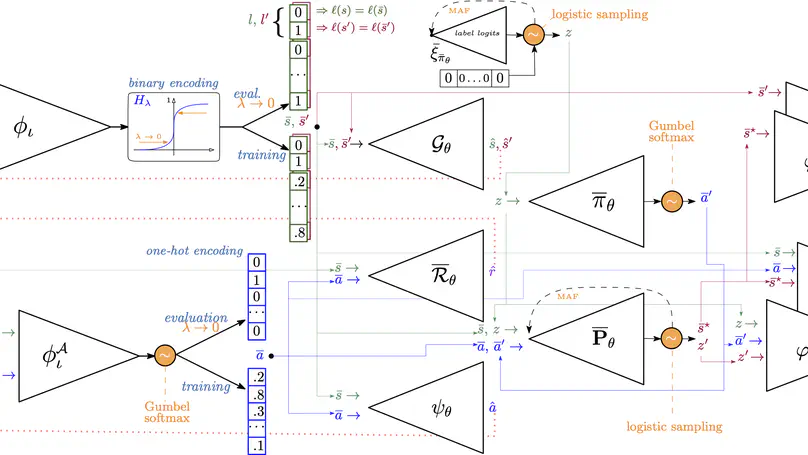
Before, I did a joint PhD within the VUB and the University of Antwerp under the supervision of Ann Nowé and Guillermo A. Pérez. My thesis focused on enabling the formal verification of deep RL policies (you can find the dissertation here).
My curriculum vitae is available here.
News
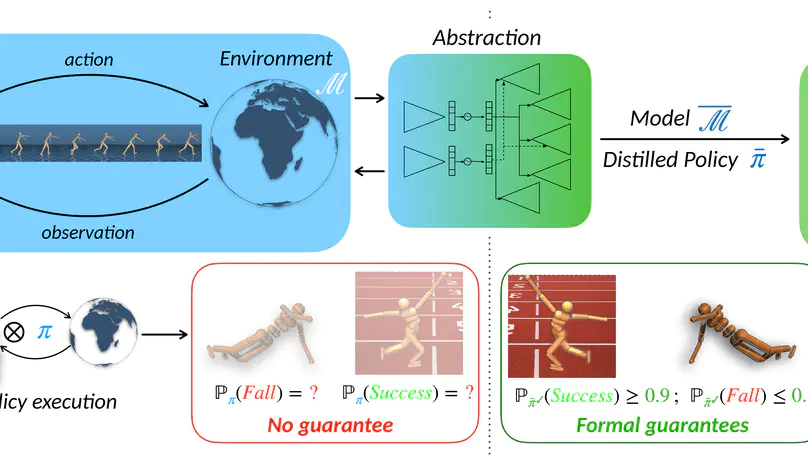
- My paper Foundation World Models for Agents that Learn, Verify, and Adapt Reliably Beyond Static Environments received the Best Blue Sky Paper Award at AAMAS 2026.
- I am organizing the Adaptive and Learning Agents Workshop at AAMAS 2026 in Paphos, Cyprus.
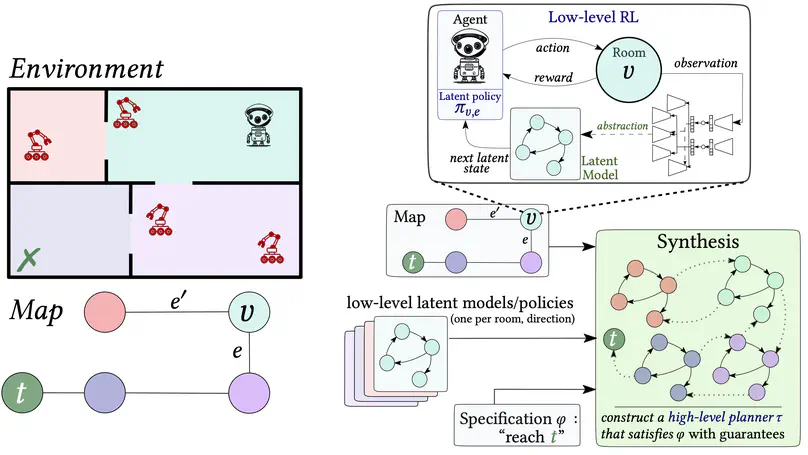
- My paper Foundation World Models for Agents that Learn, Verify, and Adapt Reliably Beyond Static Environments has been accepted to AAMAS 2026 in the Blue Sky Ideas Track.
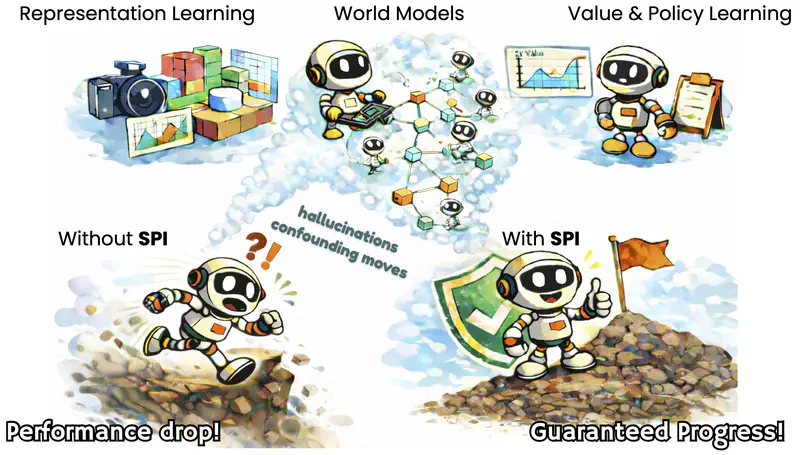
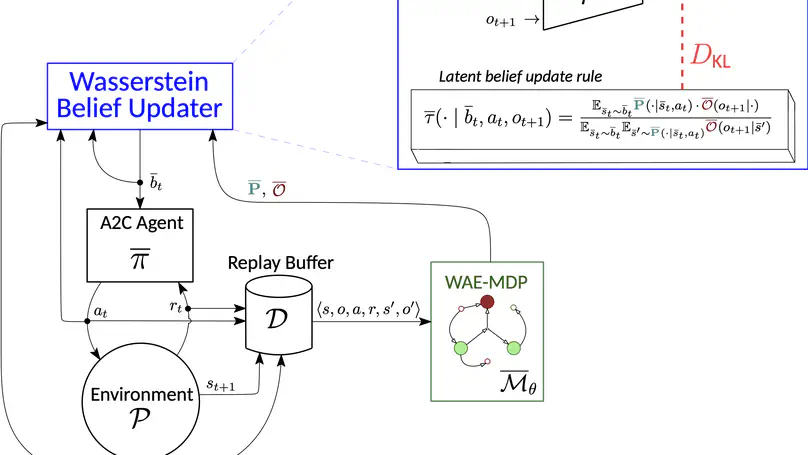
- Our paper Deep SPI: Safe Policy Improvement via World Models has been accepted to ICLR 2026. Check out the blog post here.
- Reinforcement learning
- Representation learning in RL
- Reliable and adaptive learning agents
- World Models
- Foundation Models
- Decision-making under uncertainty
Doctor of Science, Computer Science, 2024
Vrije Universiteit Brussel (VUB) and University of Antwerp, Belgium
Master in Computer Science, 2018
University of Mons (UMONS), Belgium
Bachelor in Computer Science, 2016
UMONS, Belgium


Featured Publications
Publications
Cite Code Project DOI URL Extended Abstract Technical Report