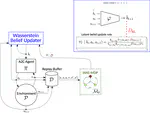
In real-world problems, decision makers often have to balance multiple objectives, which can result in trade-offs. One approach to finding a compromise is to use a multi-objective approach, which builds a set of all optimal trade-offs called a Pareto front. Learning the Pareto front requires exploring many different parts of the state- space, which can be time-consuming and increase the chances of encountering undesired or dangerous parts of the state-space. In this preliminary work, we propose a method that combines two frameworks, Pareto Conditioned Networks (PCN) and Wasserstein auto-encoded MDPs (WAE-MDPs), to efficiently learn all possible trade-offs while providing formal guarantees on the learned poli- cies. The proposed method learns the Pareto-optimal policies while providing safety and performance guarantees, especially towards unexpected events, in the multi-objective setting.
Florent Delgrange, Mathieu Reymond, Ann Nowé, Guillermo A. Pérez