Deep SPI: Safe Policy Improvement via World Models
or how to keep representation learning useful after the policy changes
This blog post is based on our ICLR 2026 paper, Deep SPI: Safe Policy Improvement via World Models. You can also find the code, and the poster.
In this post, I want to explain a simple tension in deep reinforcement learning: we often use auxiliary objectives to learn useful representations, but as soon as the policy changes, it becomes unclear whether the guarantees attached to the previous representation still say anything about the next one.
Deep SPI is our attempt to make that connection explicit. The core idea is to learn a world model together with a constrained policy-update rule, so that improving the policy in the model still guarantees improvement in the real environment up to a controlled error term, while the latent representation remains useful for the next policy as well.
Background
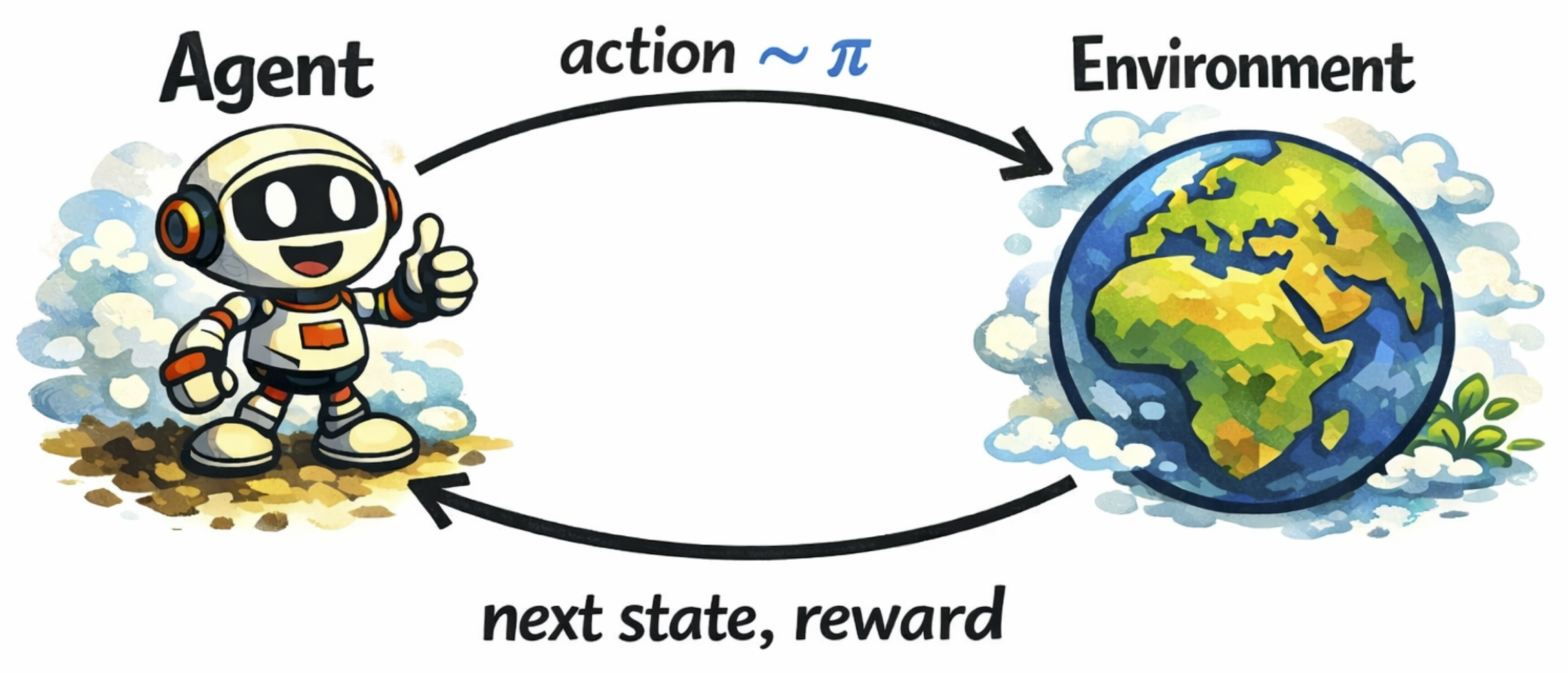
Deep RL starts from the familiar interaction loop: the agent acts, the environment transitions, and a reward comes back.
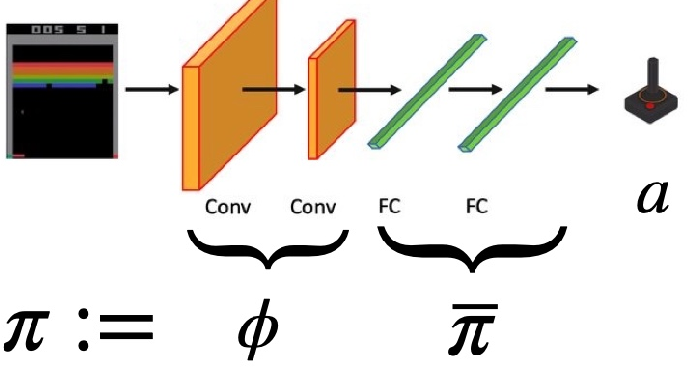
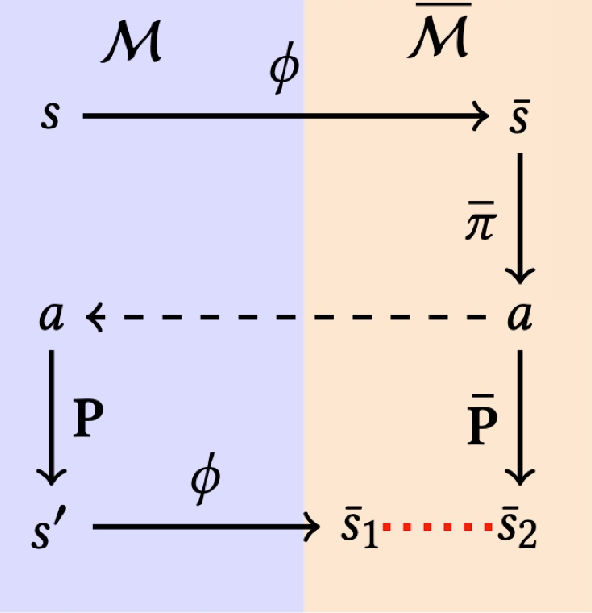
In modern settings, however, the agent does not act directly on a small symbolic state space. It acts on high-dimensional observations, such as Atari frames, so we first learn an encoder that maps the original state space $S$ to a latent space $\bar{S}$: $$ \phi \colon S \to \bar{S}. $$ The latent policy then acts on encoded states, $$ \bar{\pi} \colon \bar{S} \to \Delta(A), $$ and the deployed policy is the composition $$ \pi := \bar{\pi} \circ \phi. $$
What is a “good representation?”
For us, a good representation is not one that merely reconstructs images well. It is a representation that preserves what matters for control, namely the value induced by the policy we will actually deploy.
That is why the right quantity to keep in mind is $$ V^{\pi}(s) := \mathbb{E}\left[\sum_{t = 0}^{\infty} \gamma^t R(s_t, {a_t}) \mid s_0 = s, \quad {a_t} \sim \bar{\pi}(\cdot \mid \phi(s_t))\right]. $$ If two states are close in latent space, their values should also remain close, at least up to a controlled error. This is the property that makes value approximation, planning, and generalization meaningful.
The catch is that most auxiliary guarantees are derived on-policy. So even if the current encoder is good for the current policy, updating both can immediately invalidate the old guarantee. That is the real problem Deep SPI is built to solve.
No Way Home: When World Models and Policies Go Out of Trajectories
World models are a natural place to attack the problem because they give us two useful objects at once: a reward predictor and a transition predictor. That makes them attractive both as auxiliary tasks for learning a representation and as models in which we can plan.
But there is an obvious danger. If the world model is trained on trajectories collected under a behavioral policy $\pi_b$, then it can look good exactly where $\pi_b$ goes and still be badly wrong where the next policy wants to go.

This is the out-of-trajectory problem. The issue is not that the model is globally useless; it is that it may be miscalibrated exactly in the region that suddenly matters for the new policy. Once that happens, planning inside the model can become optimistic for the wrong reasons.
So the question becomes: how do we keep policy updates close enough to the data regime that shaped the world model, while still making progress?
Your Friendly Neighborhood Policy
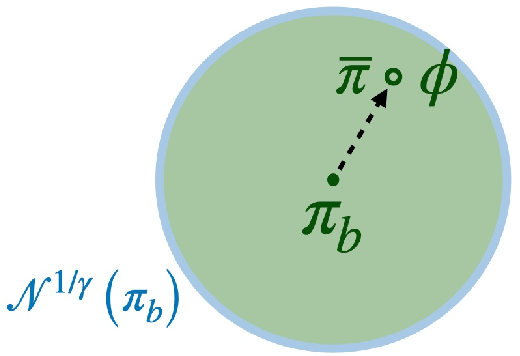
The answer in the paper is to introduce a neighborhood operator around the current policy. Instead of allowing an arbitrary jump from $\pi_b$ to a new policy $\pi$, we only consider policies whose action probabilities remain inside a trust region defined by importance-ratio bounds.
Formally, $$ \pi’ \in \mathcal{N}^{C}(\pi_b) \iff 2 - C \le \frac{\pi’(a \mid s)}{\pi_b(a \mid s)} \le C \quad \forall s,\ \forall a \in \mathrm{supp}(\pi_b(\cdot \mid s)). $$ So $\mathcal{N}^{C}(\pi_b)$ is the neighborhood of policies whose action probabilities remain in the ratio band $[2 - C, C]$ relative to the behavioral policy. The update rule then becomes $$ \pi_{n+1} \in \arg\max_{\pi’ \in \mathcal{N}^{C}(\pi_n)} \mathbb{E}_{\left(s, a\right)\, \sim\, \pi’}\left[A^{\pi_n}(s, a)\right]. $$
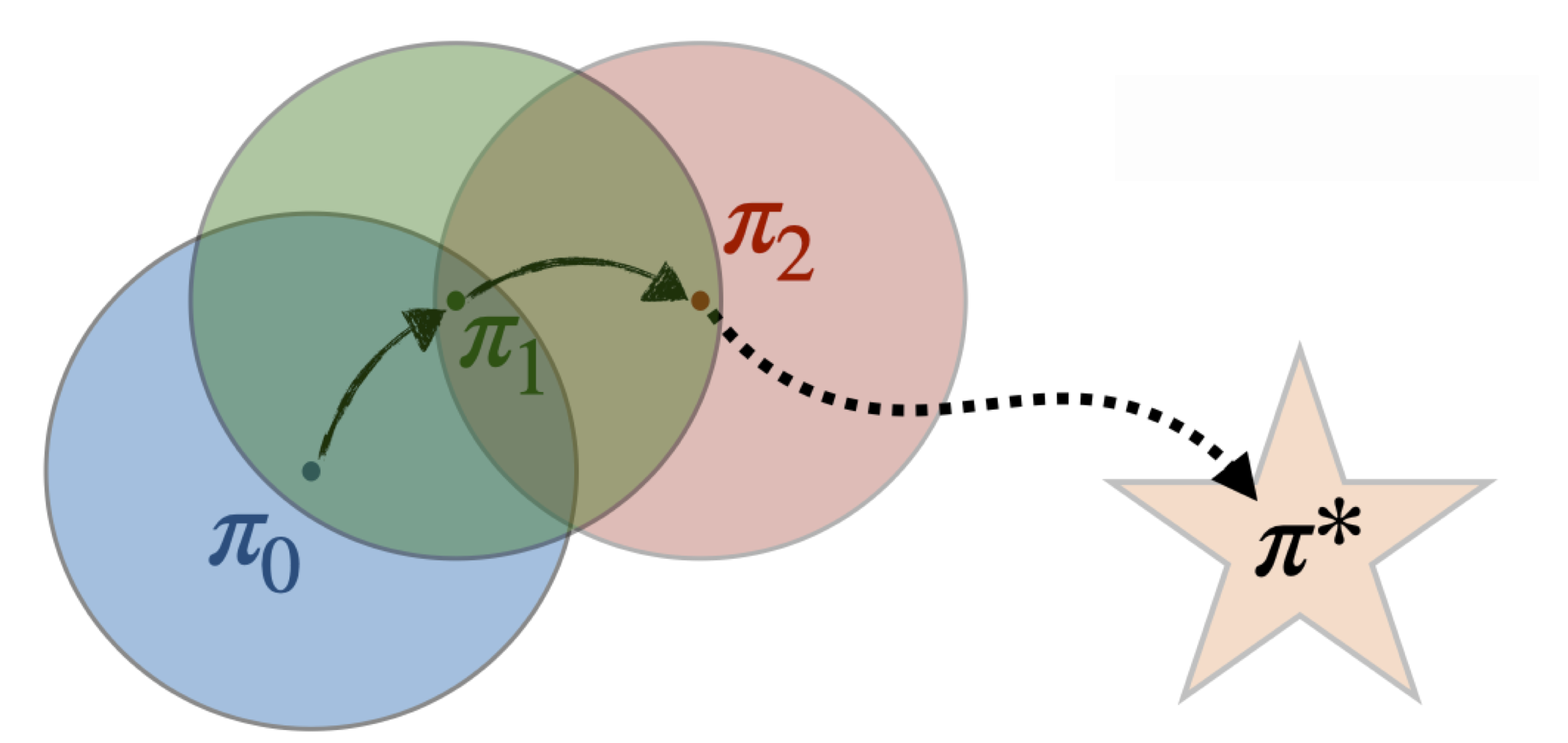

Why is this useful? Because once updates are local, Deep SPI inherits the key safe-policy-improvement story: in the paper, we proved that iterative updates improve monotonically, the sequence converges, and the next policy cannot drift arbitrarily far from the data regime that made the current world model and representation meaningful. So, Deep SPI is not about one giant policy leap. It is about a sequence of small, trustworthy moves.
With Great World Models Comes Great Representation
Once updates are local, we can ask a more refined question: what should the world model actually learn?
Learning a sound world model
Deep SPI uses a reward loss and a transition loss tied to the behavioral policy’s data. For the reward we use an $L_1$ prediction loss, and for the transition dynamics we may simply use a Euclidean norm in latent space (this is already sufficient for the guarantee, though tighter bounds may come from a more elaborate Wasserstein loss as in WAE-MDPs):
The important point is that these are local losses. They are measured on the state-action distribution induced by the behavioral policy, so they are exactly the quantities that tell us whether the world model is calibrated in the region where we currently have data.
Restricting the policy update for the next two guarantees
From this point on, the next two guarantees use the stricter neighborhood $$ \pi^{new} \in \mathcal{N}^{1/\gamma}(\pi_b). $$ This is where the discount factor becomes more than just an RL convenience: it defines an implicit horizon, or if you prefer an implicit radius, for the policy update scheme. Smaller effective horizons permit larger safe deviations, while larger horizons force the update to stay tighter. The next theorems are important precisely because they hold under this particular constraint.
Deep safe policy improvement
Under that controlled update regime, the paper proves the key transfer statement: if the policy improves enough in the world model, then it also improves in the real environment up to a local model-error term.
Here, $V^{\pi}(\mathcal{M})$ denotes the value function when running the deployed policy $\pi$ in the environment $\mathcal{M}$ from the initial state. Then the Deep SPI guarantee can be read as
That is the central SPI message of the paper: model-based improvement is not just a heuristic anymore. As long as the world model is accurate enough on the behavioral-policy data and the update stays inside the safe neighborhood, any gain in the world model transfers back to the real environment.
Deep SPI for representation learning
The representation-learning theorem is the part I find especially satisfying. It says that under the same controlled policy change, the learned latent space remains almost Lipschitz for the next policy:


Why is that good? Because it says the latent geometry is still informative for value after the policy update. That helps value approximation and planning, but it also says something important about representation collapse: if two states have very different values, the theorem prevents the encoder from mapping them all to the same latent point while keeping the guarantee intact. So the result is useful both positively, for generalization, and negatively, because it rules out a degenerate failure mode.
Across the SPI-Verse: PPO Comes Into Play
The theory naturally raises a practical question: how do we enforce the neighborhood in a modern deep RL pipeline?
PPO is the natural answer. Its clipped objective already behaves like a trust-region heuristic, so Deep SPI starts from PPO and modifies it in a way that keeps the neighborhood logic intact.
The naive idea would be to add the world-model losses directly to the PPO loss. But that would be wrong. Those losses update the encoder, so they can indirectly push the composed policy $\pi^{new} := \bar{\pi} \circ \phi$ outside the neighborhood even if the policy head alone still looks well behaved.
The fix is to fold the auxiliary terms into the utility itself: $$ U^{\pi_b}(s, a) := A^{\pi_b}(s, a) - \alpha_R \cdot L_R - \alpha_P \cdot L_P $$ and then optimize the PPO-like objective $$ L_{\mathrm{DeepSPI}}(\pi) := \mathbb{E}\left[ \min\left\{ \mathbf{r}\left(\pi\right) \cdot U^{\pi_b},\, \operatorname{clip}\left(\mathbf{r}\left(\pi\right), 1\pm\varepsilon\right) \cdot U^{\pi_b} \right\} \right], $$ where $$ \mathbf{r}(\pi)(s, a) := \frac{\pi(a \mid s)}{\pi_b(a \mid s)}. $$ In this PPO-like relaxation, we choose the clipping parameter to match the neighborhood scale, namely $$ \varepsilon = C - 1. $$ So Deep SPI keeps PPO’s trust-region behavior while making the world-model terms part of the very quantity whose local improvement is being optimized.
There is also a very practical data issue here. PPO is on-policy, which means world-model learning can easily suffer from narrow, highly correlated coverage if we collect long rollouts from only a few environments. That is exactly the wrong regime for learning a calibrated world model.


In practice, the JAX implementation matters a lot here. The move from a handful of environments with long rollouts to many environments with short rollouts gives much broader state coverage without abandoning the on-policy setup. That detail is easy to miss when reading only the theorem statements, but it is critical in the actual algorithm: a local guarantee is only helpful if the local data cover enough of the neighborhood to learn the model well.
Experiments
The payoff is that Deep SPI is not only theoretically neat. On 57 stochastic Atari environments, it is also competitive with strong behaviorals such as PPO and DeepMDPs.

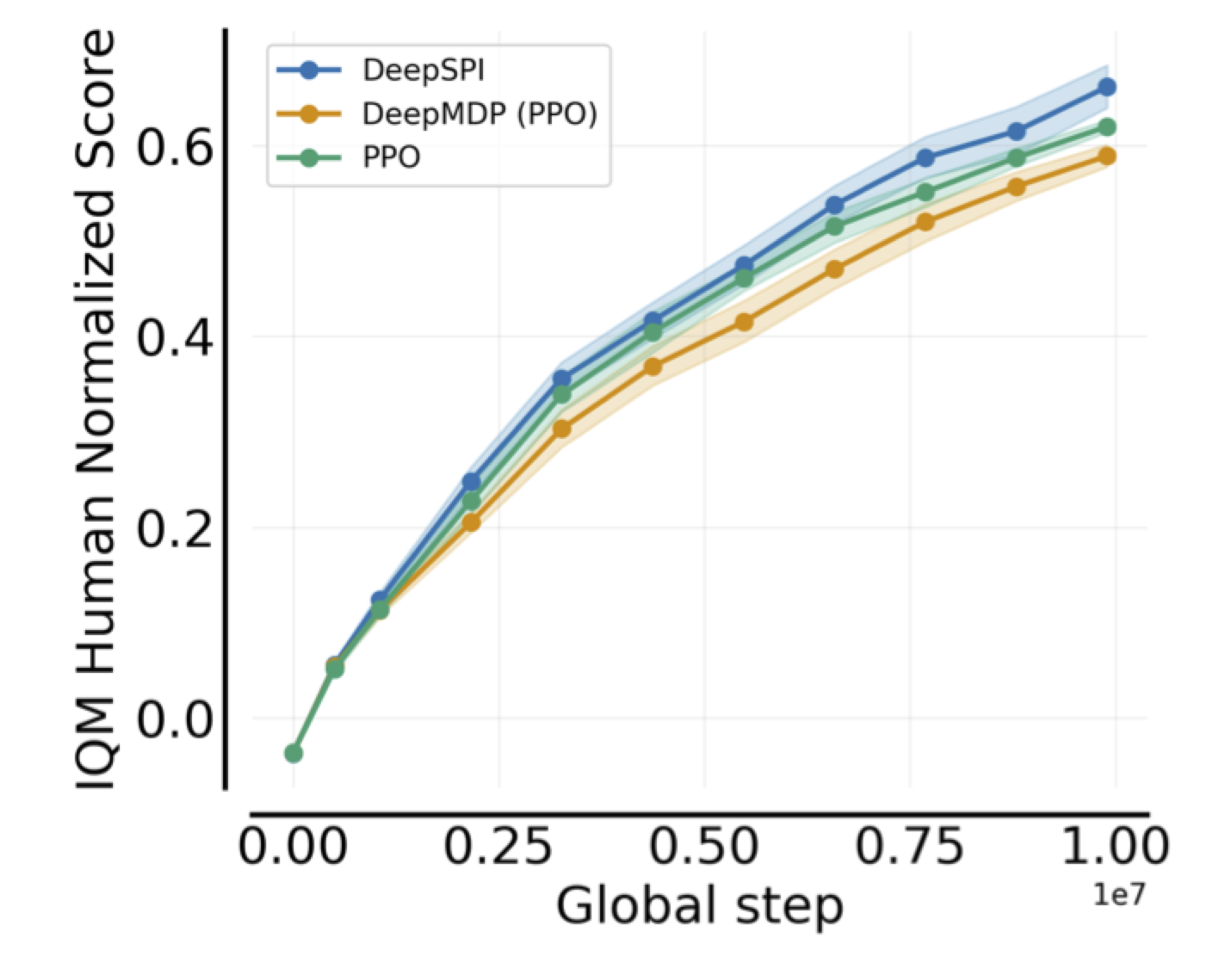
What I like about these results is that they line up with the theory. The method is not competitive in spite of the neighborhood/world-model discipline. It is competitive because that discipline prevents the update from breaking the very representation and model assumptions the algorithm relies on.
Conclusion and Future Work
The central claim of Deep SPI is that policy improvement, world-model calibration, and representation learning should not be treated as separate problems. If the representation is supposed to support policy improvement, then the update rule itself has to appear in the analysis.
That is why the neighborhood constraint matters so much. It is the bridge that lets us say, in a deep RL setting, that model-based improvement is reliable up to controlled local error, and that the representation learned today can still be useful for the next policy tomorrow.
More broadly, I think this is a useful perspective on world models in RL. They are not only tools for sample efficiency; they can also be tools for reliable policy improvement. That is the perspective behind Deep SPI, and I expect it will matter even more as world-model-based agents become larger, more general, and more autonomous.