Evaluation of deep-RL policies distilled via Variational Abstraction of Markov Decision Processes
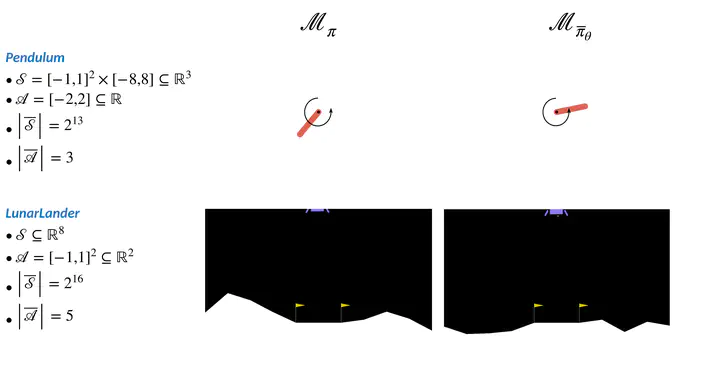
This post embeds a set of videos demonstrating the performance of our policies distilled through our VAE-MDP framework. We evaluated our method on classic OpenAI Gym environments, including CartPole, MountainCar, and Acrobot (via deep Q-learning agents), as well as Pendulum and LunarLander (via soft actor critic agents). We used TensorFlow agent as backend to learn the agent policies and we distilled simpler policies via our implementation of VAE-MDPs. The trained variational models loaded and used in this post are available in the git repository.
For each environment, we compare the average episode return produced by executing the original RL policy against the simpler, distilled one. The number of discrete states (and the number of discrete actions in the case of continuous actions) used to abstract the continuous-spaces environment is provided as output of the code snippet generating each video of distilled policies.
Load required modules
import sys
import os
path = os.path.dirname(os.path.abspath("__file__"))
sys.path.insert(0, path + '/../..')
import base64
import IPython
import importlib
import logging
logging.getLogger().setLevel(logging.ERROR)
import random
from tf_agents.environments import suite_gym, parallel_py_environment
from tf_agents.environments import tf_py_environment
from tf_agents.metrics import tf_metrics
from tf_agents.replay_buffers import tf_uniform_replay_buffer, episodic_replay_buffer
from tf_agents.drivers import dynamic_episode_driver, dynamic_step_driver
from tf_agents.trajectories import time_step as ts, policy_step, trajectory
from tf_agents.utils import common
import tensorflow as tf
tf.get_logger().setLevel('ERROR')
tf.autograph.set_verbosity(3)
import numpy as np
import pandas as pd
from reinforcement_learning import labeling_functions
from util.io.dataset_generator import map_rl_trajectory_to_vae_input
from util.io.dataset_generator import ErgodicMDPTransitionGenerator
import reinforcement_learning.environments
from reinforcement_learning.environments import perturbed_env
from policies.saved_policy import SavedTFPolicy
from policies.epsilon_mimic import EpsilonMimicPolicy
from policies.latent_policy import LatentPolicyOverRealStateAndActionSpaces
from util.io import video
import variational_mdp
import variational_action_discretizer
# set seed
seed = 42
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
def display_state_space(py_env):
print("state space shape:", py_env.observation_spec().shape)
print("state space max values:", py_env.observation_spec().maximum)
print("state space min values:", py_env.observation_spec().minimum)
def display_action_space(py_env):
if py_env.action_spec().dtype in [np.int64, np.int32]:
print("discrete action space")
print("number of discrete actions:", py_env.action_spec().maximum + 1)
else:
print("continuous action space")
print("action space shape:", py_env.action_spec().shape)
print("action space max values:", py_env.action_spec().maximum)
print("action space min values:", py_env.action_spec().minimum)
CartPole
RL policy (DQN)
with suite_gym.load('CartPole-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
display_state_space(py_env)
display_action_space(py_env)
policy_dir = '../saves/CartPole-v0/policy/'
policy = SavedTFPolicy(policy_dir)
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'pendulum_sac_policy', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer,
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
state space shape: (4,)
state space max values: [4.8000002e+00 3.4028235e+38 4.1887903e-01 3.4028235e+38]
state space min values: [-4.8000002e+00 -3.4028235e+38 -4.1887903e-01 -3.4028235e+38]
discrete action space
number of discrete actions: 2
avg. episode return: 200
Distilled policy
vae_mdp = variational_mdp.load(
'../../saves/CartPole-v0/models/vae_LS9_ER10.0-decay=1e-05-min=0_KLA0.0-growth=5e-05_TD0.67-0.50_activation=leaky_relu_lr=0.001_seed=20210510_PER-P_exp=0.33-WIS_exponent=0.4-WIS_growth=7e-05_buckets_based_params=latent_policy/base',
discrete_action=True,
step=980000
)
print("VAE MDP loaded")
print("size of the latent state space: {:d}".format(2 ** vae_mdp.latent_state_size))
with suite_gym.load('CartPole-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
tf_env = vae_mdp.wrap_tf_environment(tf_env, labeling_functions['CartPole-v0'])
policy = vae_mdp.get_latent_policy()
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'cartpole_distilled_policy', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
VAE MDP loaded
size of the latent state space: 512
avg. episode return: 200
MountainCar
RL policy (DQN)
with suite_gym.load('MountainCar-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
display_state_space(py_env)
display_action_space(py_env)
policy_dir = '../saves/MountainCar-v0/dqn_policy/'
policy = SavedTFPolicy(policy_dir)
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'mountain_car_dqn', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer,
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
state space shape: (2,)
state space max values: [0.6 0.07]
state space min values: [-1.2 -0.07]
discrete action space
number of discrete actions: 3
avg. episode return: -101.6
Distilled policy
vae_mdp = variational_mdp.load(
'../../saves/MountainCar-v0/models/vae_LS10_ER10.0-decay=1e-05-min=0_KLA0.0-growth=5e-05_TD0.67-0.50_activation=leaky_relu_lr=0.001_seed=20210517_PER-P_exp=0.33-WIS_exponent=0.4-WIS_growth=7.5e-05_buckets_based_params=latent_policy/base/',
discrete_action=True,
step=580000
)
print("VAE MDP loaded")
print("size of the latent state space: {:d}".format(2 ** vae_mdp.latent_state_size))
with suite_gym.load('MountainCar-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
tf_env = vae_mdp.wrap_tf_environment(tf_env, labeling_functions['MountainCar-v0'])
policy = vae_mdp.get_latent_policy()
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env,
'mountain_car_distilled_policy',
num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
VAE MDP loaded
size of the latent state space: 1024
avg. episode return: -102.9
Acrobot
RL Policy (DQN, trained in an environment with random initial states)
with suite_gym.load('Acrobot-v1') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
display_state_space(py_env)
display_action_space(py_env)
policy_dir = '../saves/AcrobotRandomInit-v1/dqn_policy/'
policy = SavedTFPolicy(policy_dir)
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'acrobot_dqn', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer,
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
state space shape: (6,)
state space max values: [ 1. 1. 1. 1. 12.566371 28.274334]
state space min values: [ -1. -1. -1. -1. -12.566371 -28.274334]
discrete action space
number of discrete actions: 3
avg. episode return: -69.8
Distilled policy
vae_mdp = variational_mdp.load(
'../../saves/Acrobot-v1/models/vae_LS13_ER10.0-decay=7.5e-05-min=0_KLA0.0-growth=7.5e-05_TD0.67-0.50_activation=relu_lr=0.0001_seed=33333_PER-P_exp=0.3-WIS_exponent=0.4-WIS_growth=7e-05_buckets_based_epsilon_greedy=0.5-decay=1e-05_params=latent_policy/base/',
discrete_action=True,
step=1330000,
)
print("VAE MDP loaded")
print("size of the latent state space: {:d}".format(2 ** vae_mdp.latent_state_size))
with suite_gym.load('Acrobot-v1') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
tf_env = vae_mdp.wrap_tf_environment(tf_env, labeling_functions['Acrobot-v1'])
policy = vae_mdp.get_latent_policy()
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env,
'acrobot_distilled_policy',
num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
VAE MDP loaded
size of the latent state space: 8192
avg. episode return: -86.3
Pendulum
RL policy (SAC, trained in an environment with random initial states)
with suite_gym.load('Pendulum-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
display_state_space(py_env)
display_action_space(py_env)
sac_policy_dir = '../saves/PendulumRandomInit-v0/sac_policy'
policy = SavedTFPolicy(sac_policy_dir)
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'pendulum_sac_policy', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer,
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
state space shape: (3,)
state space max values: [1. 1. 8.]
state space min values: [-1. -1. -8.]
continuous action space
action space shape: (1,)
action space max values: 2.0
action space min values: -2.0
avg. episode return: -154.362717
Distilled policy
vae_mdp = variational_action_discretizer.load(
'../../saves/PendulumRandomInit-v0/models/vae_LS13_ER10.0-decay=7.5e-05-min=0_KLA0.0-growth=7.5e-05_TD0.67-0.50_activation=relu_lr=0.0001_seed=22222222/sac_policy/action_discretizer/LA3_ER10.0-decay=7.5e-05-min=0_KLA0.0-growth=7.5e-05_TD0.50-0.33_PER-P_exp=0.3-WIS_exponent=0.4-WIS_growth=1e-05_loss_based_epsilon_greedy=0.5-decay=1e-05/base',
step=350000
)
print("VAE MDP loaded")
print("size of the latent state space: {:d}".format(2 ** vae_mdp.latent_state_size))
print("size of the latent action space: {:d}".format(vae_mdp.number_of_discrete_actions))
with suite_gym.load('Pendulum-v0') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
tf_env = vae_mdp.wrap_tf_environment(tf_env, labeling_functions['Pendulum-v0'])
policy = vae_mdp.get_latent_policy()
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'distilled_policy', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
VAE MDP loaded
size of the latent state space: 8192
size of the latent action space: 3
avg. episode return: -181.244797
Continuous LunarLander
RL policy (SAC)
with suite_gym.load('LunarLanderContinuous-v2') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
display_state_space(py_env)
display_action_space(py_env)
sac_policy_dir = '../saves/LunarLanderContinuous-v2/sac_policy'
policy = SavedTFPolicy(sac_policy_dir)
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'lunar_lander_sac_policy', num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer,
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
state space shape: (8,)
state space max values: 3.4028235e+38
state space min values: -3.4028235e+38
continuous action space
action space shape: (2,)
action space max values: 1.0
action space min values: -1.0
avg. episode return: 287.551422
Distilled policy
vae_mdp = variational_action_discretizer.load(
'../../saves/LunarLander-v2/models/vae_LS16_ER10.0-decay=1e-05-min=0_KLA0.0-growth=5e-05_TD0.67-0.50_activation=relu_lr=0.0001_seed=22222/sac_policy/action_discretizer/LA5_ER1.0-decay=1e-05-min=0_KLA0.0-growth=5e-05_TD0.25-0.17_PER-P_exp=0.3-WIS_exponent=0.4-WIS_growth=1e-05_loss_based/base',
step=630000
)
print("VAE MDP loaded")
print("size of the latent state space: {:d}".format(2 ** vae_mdp.latent_state_size))
print("size of the latent action space: {:d}".format(vae_mdp.number_of_discrete_actions))
with suite_gym.load('LunarLanderContinuous-v2') as py_env:
py_env.reset()
tf_env = tf_py_environment.TFPyEnvironment(py_env)
tf_env = vae_mdp.wrap_tf_environment(tf_env, labeling_functions['LunarLanderContinuous-v2'])
policy = vae_mdp.get_latent_policy()
num_episodes=10
reward_metric = tf_metrics.AverageReturnMetric()
video_observer = video.VideoEmbeddingObserver(py_env, 'lunar_lander_distilled_policy',
num_episodes=num_episodes)
dynamic_episode_driver.DynamicEpisodeDriver(
tf_env, policy, num_episodes=num_episodes,
observers=[
reward_metric,
video_observer
]).run()
tf.print('avg. episode return:', reward_metric.result())
embed_mp4(video_observer.file_name)
VAE MDP loaded
size of the latent state space: 65536
size of the latent action space: 5
avg. episode return: 270.840149