Composing RL policies, with formal guarantees
Implementation of the techniques presented in our paper Composing Reinforcement Learning Policies, with Formal Guarantees. The source code can be found on GitHub.
This project aims at combining reinforcement learning (RL) and reactive synthesis to equip learning agents with reliable control policies in large, complex environments.
While deep RL is very effective for allowing learning agents to solve complex tasks, (1) it requires (extensive) reward engineering to align the user’s intentions with the learned agent’s behaviors, and (2) the learned agent’s policies are not reliable (no guarantee). Reactive synthesis on the other hand produces reliable control policies that are guaranteed to meet specifications provided in intuitive formal language. However, this requires access to an explicit environment’s model, which is rarely possible in complex environments; even when it is, synthesis does not scale to high-stakes scenarios.
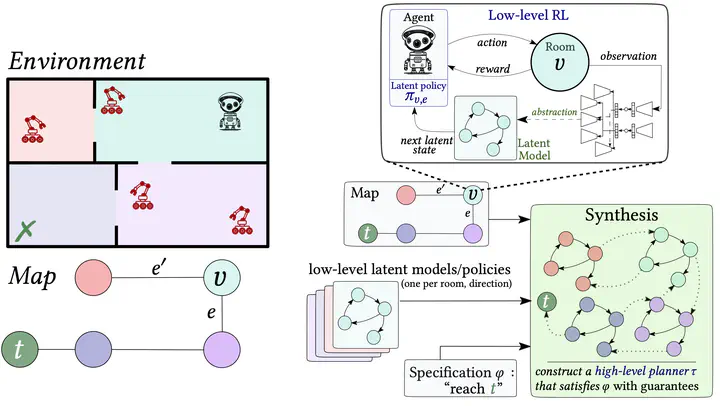
This proposed framework tackles those issues through a hierarchical decomposition of the environment into sub-regions/sections that we call “rooms”. Given a graph (e.g, “map”, “skill graph”) that represent this decomposition, we apply RL in each room to get low-level policies satisfying low-level specifications. Then, we apply synthesis to produce a high-level planner that selects which policy to apply in each room. The resulting method provides guarantees on the resulting agent’s controller, allows for a separation of concerns, and mitigates reward engineering.
The approach relies on learning world models and discrete latent spaces, which enables the formal verification of the low-level policies (via model-checking). Reactive synthesis then composes with the low-level RL policies and the world models to produce high-level planners with guarantees.

New RL algorithm and environments
The project also includes WAE-DQN, an RL algorithm learning a discrete and verifiable world model along with its policy, and new “two-level” environments:
- A large, parameterizable grid world with moving obstacles
- A 8-room A ViZDoom scenario with ennemies randomly spawning on the map at regular interval.
The two environments come with low- and high-level variants. In the low-level variant, the agent is placed in a room of the two-level environment and its goal is to reach the exit safely, by avoiding moving obstacles. In the high-level variant, the goal of the agent is to navigate safely through the rooms composing the environment to reach a target location.