A TensorFlow 2 implementation of Variational Markov Decision Processes, a framework allowing to (i) distill policies learned through (deep) reinforcement learning and (ii) learn discrete abstractions of continuous environments, the two with bisimulation guarantees.
The source code provided allows replicating the experiments presented in the paper Distillation of RL Policies with Formal Guarantees via Variational Abstraction of Markov Decision Processes.
The source code is available on GitHub.
Florent Delgrange
Post-doctoral Researcher in Computer Science
Publications
VenueAAAI
Distillation of RL Policies with Formal Guarantees via Variational Abstraction of Markov Decision Processes
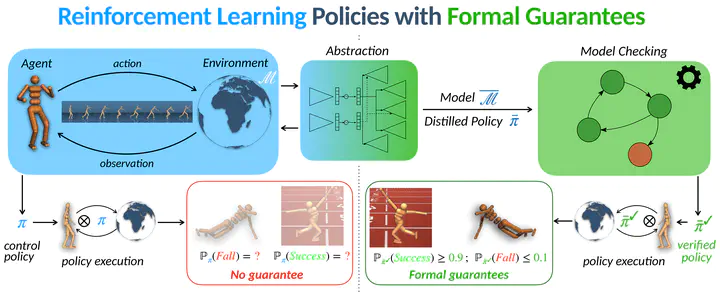
We consider the challenge of policy simplification and verification in the context of policies learned through reinforcement learning (RL) in continuous environments. In well-behaved settings, RL algorithms have convergence guarantees in the limit. While these guarantees are valuable, they are insufficient for safety-critical applications. Furthermore, they are lost when applying advanced techniques such as deep-RL. To recover guarantees when applying advanced RL algorithms to more complex environments with (i) reachability, (ii) safety-constrained reachability, or (iii) discounted-reward objectives, we build upon the DeepMDP framework introduced by Gelada et al. to derive new bisimulation bounds between the unknown environment and a learned discrete latent model of it. Our bisimulation bounds enable the application of formal methods for Markov decision processes. Finally, we show how one can use a policy obtained via state-of-the-art RL to efficiently train a variational autoencoder that yields a discrete latent model with provably approximately correct bisimulation guarantees. Additionally, we obtain a distilled version of the policy for the latent model.

