Intelligent agents are computational entities that autonomously interact with an environment to achieve their design objectives. On the one hand, reinforcement learning (RL) encompasses machine learning techniques that allow agents to learn by trial and error a control policy, prescribing how to behave in the environment. Although RL is proven to converge to an optimal policy under some assumptions, the guarantees vanish with the introduction of advanced techniques, such as deep RL, to deal with high-dimensional state and action spaces. This prevents them from being widely adopted in real-world safety-critical scenarios.
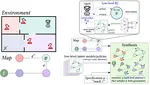
On the other hand, formal methods are mathematical techniques that provide guarantees about the correctness of systems. In particular, model checking allows formally verifying the agent’s behaviors in the environment. However, this typically relies on a formal description of the interaction, as well as conducting an exhaustive exploration of the state space. This poses significant challenges because the environment is seldom explicitly accessible. Even when it is, model checking suffers from the curse of dimensionality and struggles to scale to high-dimensional state and action spaces, which are common in deep RL.
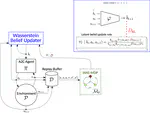
In this thesis, we leverage the strengths of deep RL to handle realistic scenarios while integrating formal methods to provide guarantees on the agent’s behaviors. Specifically, we activate formal verification of deep RL policies by learning a latent model of the environment, over which we distill the deep RL policy. The outcome is amenable for model checking and is endowed with bisimulation guarantees, which allows to lift the verification results to the original environment.
Beyond distillation, we show that our method is also useful for learning representation in the context of deep RL, facilitating the learning of the policy in complex environments. In particular, we present a framework for partially observable environments. We finally show how our method can be leveraged in the context of synthesis, i.e., the automatic generation of controllers from logical specifications with formal guarantees. Precisely, we present how deep RL components learned via our latent space models facilitate synthesis in typically intractable environments.