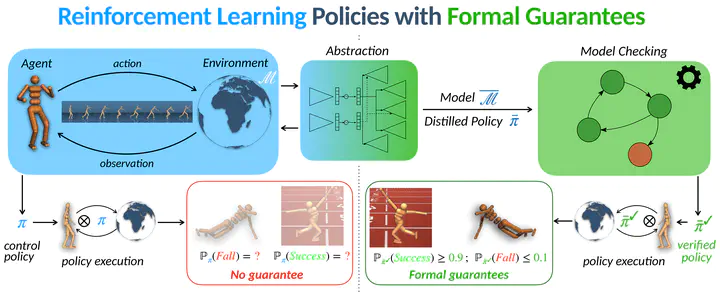
A TensorFlow 2 implementation of Variational Markov Decision Processes, a framework allowing to (i) distill policies learned through (deep) reinforcement learning and (ii) learn discrete abstractions of continuous environments, the two with bisimulation guarantees.
The source code provided allows replicating the experiments presented in the paper Distillation of RL Policies with Formal Guarantees via Variational Abstraction of Markov Decision Processes.
The source code is available on GitHub.

