Composing Reinforcement Learning Policies, with Formal Guarantees
Abstract
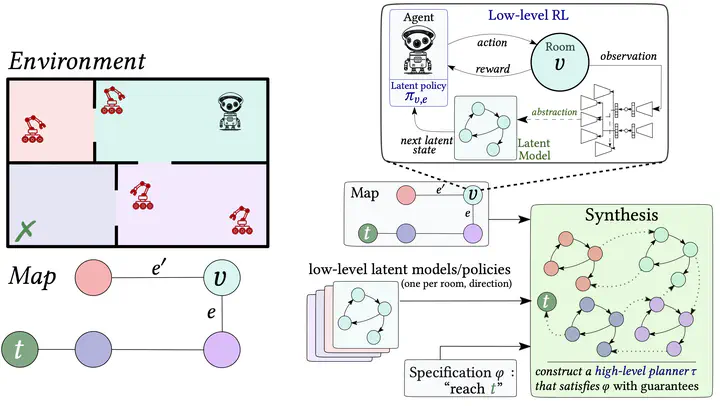
We propose a novel framework to controller design in environments with a two-level structure: a known high-level graph (“map”) in which each vertex is populated by a Markov decision process, called a “room”. The framework “separates concerns” by using different design techniques for low- and high-level tasks. We apply reactive synthesis for high-level tasks: given a specification as a logical formula over the high-level graph and a collection of low-level policies obtained together with “concise” latent structures, we construct a “planner” that selects which low-level policy to apply in each room. We develop a reinforcement learning procedure to train low-level policies on latent structures, which unlike previous approaches, circumvents a model distillation step. We pair the policy with probably approximately correct guarantees on its performance and on the abstraction quality, and lift these guarantees to the high-level task. These formal guarantees are the main advantage of the framework. Other advantages include scalability (rooms are large and their dynamics are unknown) and reusability of low-level policies. We demonstrate feasibility in challenging case studies where an agent navigates environments with moving obstacles and visual inputs.

This work received the Best Poster Award at BeNeRL 2025.